Vulkan synchronization
Synchronization is probably the most complex concept in Vulkan. The API is a bit rough around the edges. It also deals with abstract concepts like memory dependencies and image layouts. The bugs can be hard to detect and fix. In this article, we will cover the following topics:
- differences between Vulkan synchronization objects,
- vkCmdPipelineBarrier2(),
- execution and memory dependencies,
- synchronization with swapchain,
- frames in flight.
This is the second article in the series. Previously, in “Vulkan initialization”, we’ve seen how to initialize Vulkan. We’ve discussed swapchain and command buffers. Both of these concepts will be relevant.
It might seem unusual to discuss synchronization right after we have finished initializing Vulkan. Yet as you will see in both “Vulkan resources” and “A typical Vulkan frame”, this concept permeates through most other API surfaces.
Vulkan synchronization rules
Here are the general rules for Vulkan synchronization:
Command queuesrun independently of each other.- When submitted to
queueA,command buffersexecute in the specified order. - Unless an order is enforced by barriers/renderpass/sync primitives`:
- Submitted
commandsmay be executed in parallel, - Submitted
commandsmay be executed out-of-order.
- Submitted
If you have only 1 command queue (which is the simplest case), rule 1 can be ignored. You could use many queues e.g. for async compute or transfer. We will later learn about VkSemaphore used to handle these cases.
Rule 2 only describes the order of execution start. It does not specify which command will end first. Nor does it deal with dependencies. Along with rule 3, it should guide your mental model. If you submit commands to a command buffer, they will start in the specified order. They may finish in a random order. What if one command uses a resource that was written to in the previous pass? E.g. it samples from the previous pass’ attachment? This is where Vulkan synchronization comes in. Let’s discuss different use cases.
The only exceptions to synchronization are commands between
vkCmdBeginRenderPass()andvkCmdEndRenderPass().
Synchronization methods in Vulkan
As expected, there are many different methods to synchronize work in Vulkan. Selecting the right one depends on:
- What we want to synchronize. E.g. commands, queues, or CPU with GPU.
- Order of commands in a single queue. E.g. pipeline barrier instead of
VkEvent. - If the programmer can signal the change manually. E.g. there is no API to signal
VkSemaphoreandVkFence.
Let’s describe each synchronization method in Vulkan.
Pipeline barriers
Used to split the time into ‘before’ and ‘after’ the barrier. Added between 2 different, consecutive Vulkan commands that have some dependency. E.g. the first command draws to an image and the 2nd wants to sample this image in the fragment shader. Can be used for image layout transitions (more on that in “Vulkan resources”). Pipeline barriers can cause stalling, as certain steps have to be finished before we kick off new work. We will go into more detail in the next paragraphs.
Pipeline barriers are a good choice to add dependency between commands that are 1) right after one another and 2) are in a single queue. They are also used for image layout transitions.
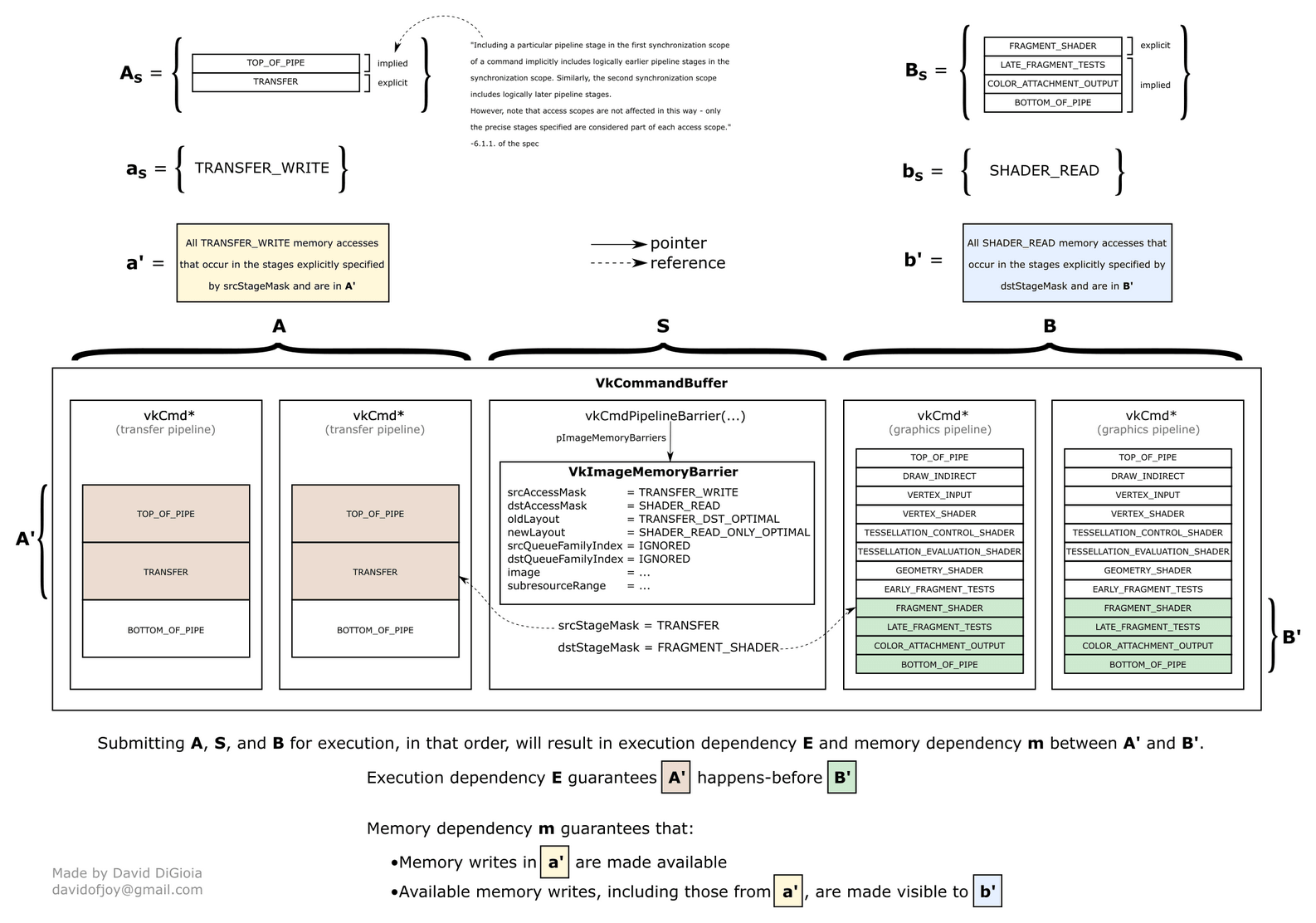
Barriers API schematic. Image by David DiGioia’s vulkan-diagrams. Available under MIT License.
Subpass dependencies (VkSubpassDependency)
We will look closer at subpasses in “A typical Vulkan frame”. This feature is quite rare in practice. It exists mostly for the sake of mobile tile-oriented renderers. Subpass dependencies are similar to pipeline barriers but they are part of the definition of VkRenderPass. Unfortunately, this is also their main weakness. Unless you have a render graph, it might be hard to track access to each image. With pipeline barriers, you can just store “the last layout/usage” for each resource.
Subpass dependencies are not available if you use the
VK_KHR_dynamic_renderingdevice extension. This should not come as a surprise, as the entire goal of this extension is to remove subpasses. As a reward, you get a much more pleasant render pass API.
Subpass dependencies are a good choice if you are already using subpasses (usually on mobile) and if while defining VkRenderPass, you already know what was the previous access to the resource.
VkEvent
VkEvents are used when all commands after vkCmdWaitEvents() have to wait for the same event. You can signal/unsignal events 1) using a command (vkCmdSetEvent(), vkCmdResetEvent()) and 2) from the host CPU device (vkSetEvent(), vkResetEvent()). Only the GPU can wait for an event (vkCmdWaitEvents()), the host cannot. Example:
vkCmdDraw(..). Starts executingdraw command 1.vkCmdSetEvent(event1). The event will be signaled afterdraw command 1is done.vkCmdDispatch(...). Starts executingcompute command A. It has nothing in common with thedraw command 1i.e. has no dependencies. It does not wait fordraw command 1to be done. Both can run in parallel.vkCmdWaitEvents(event1). At this point, both draw/compute commands execute in parallel. This step blocks the start of the next command tilldraw command 1is done. We do not care about the status ofcompute command A.vkCmdDraw(..). Starts executingdraw command 2, afterdraw command 1is done. Thecompute command Amight still be running in parallel, which saturates the GPU with work.
As you can see, compute command A can run parallel both with draw command 1 and draw command 2. We define an explicit dependency between draw command 1 and draw command 2. Alternatively, you could have also created a pipeline barrier before draw command 2. You can specify concrete resources (e.g. VkImages) that create this dependency. The driver might schedule the work optimally with only a barrier. If you have many different passes, keeping track of barriers might be complicated.
The simplicity of VkEvents and their inherent parallelism is their main strength.
VkEvent-based synchronization is a good choice to add dependency between commands in a single queue, while still allowing for other work to be done without stalling.
VkEventsare sometimes known as “split barriers”. Given it has 2 parts (vkCmdSetEvent()andvkCmdWaitEvents()), it’s not hard to see why.
VkSemaphore
Use VkSemaphores for synchronization between many queues. There is no API to signal/unsignal a semaphore. VkSemaphore can be used with vkQueueSubmit(). VkSubmitInfo contains both VkSemaphore* pWaitSemaphores and VkSemaphore* pSignalSemaphores fields. Example you have probably seen are swapchain images:
- vkAcquireNextImageKHR(). Signals once the next swapchain image is acquired.
- vkQueueSubmit(). Submit
command buffersthat will draw to a swapchain image. Therefore, it has to wait for the swapchain image acquire semaphore. Signals another semaphore after the submitted command buffers complete execution. - vkQueuePresentKHR(). Waits for queue submit finished semaphore. The image is presented once its new content has been written.
We will see this example in more detail later on.
VkSemaphore is a good choice to synchronize between many vkQueueSubmits() or when adding synchronization with the swapchain mechanism.
VkFence
Blocks CPU thread until submitted job finishes. There are only 4 operations allowed using VkFence:
- vkResetFences(). Unsignals the fence. Notice there is no way for the user to signal the fence!
- vkGetFenceStatus().
- vkDestroyFence().
- vkWaitForFences(). Blocks CPU thread. Raison d’etre.
VkFence is a good choice when you want to block CPU thread till a certain event happens. Often used at the start of the frame to prevent modifying resources still used by previous frames (e.g. writing to uniform buffers). We will explore the concept of frames in flight in the later part of this article.
vkDeviceWaitIdle() and vkQueueWaitIdle()
Block the CPU thread till all outstanding queue operations finish. Applies to either a logical device or a single queue. In my Rust-Vulkan-TressFX project, this function is only used once - when the user wants to quit the app. We wait for all the work to finish before we start destroying Vulkan objects.
This may seem similar to the VkFence. The difference is, that vkDeviceWaitIdle() and vkQueueWaitIdle() do not take an argument that denotes any particular event. Both just wait for all the work to drain.
Other synchronization methods
In Vulkan 1.2 VK_KHR_timeline_semaphore became core. As described in Khronos Group’s “Vulkan Timeline Semaphores” blog post it’s a superset of VkSemaphore and VkFence.
You can also stall the CPU using VK_QUERY_RESULT_WAIT_BIT. It waits for query results to be available.
Vulkan pipeline barrier semantics
Let’s imagine we have 2 render passes. The first pass writes to an image as a color attachment. The second pass reads the image inside the fragment shader. This introduces a dependency between the passes: “Before we execute pass 2 fragment shader, please finish writing to the color attachment in pass 1”. If we did not introduce this dependency we would have a read-after-write error. This example uses 2 pipeline stages: VK_PIPELINE_STAGE_2_FRAGMENT_SHADER_BIT (execution of fragment shader) and VK_PIPELINE_STAGE_2_COLOR_ATTACHMENT_OUTPUT_BIT (writing to the color attachment).
What is VK_PIPELINE_STAGE_2_*?
In Vulkan, each command goes through pipeline stages. The most popular pipeline stages are (in order of implicit execution):
VK_PIPELINE_STAGE_2_TOP_OF_PIPE_BITVK_PIPELINE_STAGE_2_DRAW_INDIRECT_BITVK_PIPELINE_STAGE_2_VERTEX_INPUT_BITVK_PIPELINE_STAGE_2_VERTEX_SHADER_BITVK_PIPELINE_STAGE_2_TESSELLATION_CONTROL_SHADER_BITVK_PIPELINE_STAGE_2_TESSELLATION_EVALUATION_SHADER_BITVK_PIPELINE_STAGE_2_GEOMETRY_SHADER_BITVK_PIPELINE_STAGE_2_FRAGMENT_SHADER_BITVK_PIPELINE_STAGE_2_EARLY_FRAGMENT_TESTS_BITVK_PIPELINE_STAGE_2_LATE_FRAGMENT_TESTS_BITVK_PIPELINE_STAGE_2_COLOR_ATTACHMENT_OUTPUT_BITVK_PIPELINE_STAGE_2_TRANSFER_BITVK_PIPELINE_STAGE_2_COMPUTE_SHADER_BITVK_PIPELINE_STAGE_2_BOTTOM_OF_PIPE_BIT
There are
VkPipelineStageFlagBitsandVkPipelineStageFlagBits2. Both versions have the same values if similar stages exist (e.g. 0x08 for*_VERTEX_SHADER_BIT). The difference is, thatVkPipelineStageFlagBitsare 32-bit whileVkPipelineStageFlagBits2are 64-bit. Yes, Khronos Group ran out of bits in a 32-bit mask. They had to change the type. Didn’t I say that the API is a bit clunky?
Refer to VkPipelineStageFlagBits2 docs for a complete list. As not all stages make sense for every command, the VkPipelineStageFlagBits2 are a bit clunky to use. Let’s look at the pipeline stages that matter for the most popular Vulkan commands:
- vkCmdDraw(). Used to render triangles to attachments. Usually does something in stages for
*_VERTEX_SHADER_BITand*_FRAGMENT_SHADER_BIT. Depth and stencil operations (both tests and writes) are in stages for*_EARLY_FRAGMENT_TESTS_BITand*_LATE_FRAGMENT_TESTS_BIT. We have already seen*_COLOR_ATTACHMENT_OUTPUT_BITthat designates the final write. There are a lot of other stages implied by this command. But*_COMPUTE_SHADER_BIT? This one is nonsensical. - vkCmdDispatch(). Used to dispatch compute shader. Ignores anything besides
*_COMPUTE_SHADER_BITand a few special stages. - vkCmdClearColorImage(). Used to clear regions of a color image, takes VkClearColorValue as a parameter. Not surprisingly,
*_CLEAR_BITdenotes this particular stage. You can also use*_TRANSFER_BITwhich already includes*_CLEAR_BIT. - vkCmdFillBuffer(). Used to fill the buffer with a 4-byte word (e.g. zero it or 0xffffffff). The docs say: “vkCmdFillBuffer is treated as a “transfer” operation for the purposes of synchronization barriers.”. Not exactly descriptive as
*_TRANSFER_BITis a combination of*_COPY_BIT | *_BLIT_BIT | *_RESOLVE_BIT | *_CLEAR_BIT | *_ACCELERATION_STRUCTURE_COPY_BIT_KHR.
There are several special stages like *_TOP_OF_PIPE_BIT (start of a command) and *_BOTTOM_OF_PIPE_BIT (end of a command). With these 2 values you can express the following dependency: “Before we start this command (*_TOP_OF_PIPE_BIT), please finish ANY other thing you are doing (*_BOTTOM_OF_PIPE_BIT)”. That’s a suboptimal barrier. Useful for debugging or as a placeholder. There is even an aptly named *_ALL_COMMANDS_BIT if needed.
Please note that in Vulkan, the pipeline stages have an implicit order. E.g. vertex shader is always run before fragment shaders. Waiting for *_VERTEX_SHADER_BIT | *_FRAGMENT_SHADER_BIT | *_COLOR_ATTACHMENT_OUTPUT_BIT to complete is equal to *_COLOR_ATTACHMENT_OUTPUT_BIT as it is the latest stage to finish.
If only that was all that there is about synchronization!
VkAccessFlagBits2, execution and memory dependencies
In Vulkan, when you write a value onto GPU DDR memory, there is no guarantee that it will be written immediately. From what we know, it will sit in some cache first. When we defined VkPipelineStageFlagBits2 we specified an execution dependency chain. Unfortunately, due to caches, execution dependency is not enough to guarantee safe access to the memory that was just written. There exist 4 main hazards:
Read-after-read. No dependencies. In older Vulkan specifications,execution dependency(VkPipelineStageFlagBits2) was mentioned in passing. At some point, even Khronos Group admitted it was not needed.Write-after-read. Ensure that the read finishes before the memory is overwritten.Execution dependency(VkPipelineStageFlagBits2) is enough to safeguard memory access.Read-after-write. Ensure that the write happens before the subsequent read. Requires amemory dependency.Write-after-write. Both operations want to write to the same memory address. Ensure that the later write is the ‘final’ value. This implies an ordering. Requires amemory dependency.
The exact wording in Vulkan 1.3 spec, chapter 7 is (emphasis mine): “Execution dependencies alone are not sufficient to guarantee that values resulting from writes in one set of operations can be read from another set of operations.”.
In other words,
execution dependenciesdefine which stages can be executed in parallel. E.g. vertex stage at the same time as fragment stage of a previous pass. It disregards the topic of memory altogether.
A memory dependency makes the result of a write available. Then it makes it visible. Availability and visibility are states of a write operation. They track how far the write has permeated the system, i.e. who is able to observe the write. One explanation I found compares availability to a cache flush (write cache to main memory) and visibility to cache invalidate (mark all caches as invalid so that a subsequent operation has to refer to the main memory). GPU can have many caches (e.g. separate L1 for each multiprocessor). In “Vulkan Synchronization | ‘Understand Fences, Semaphores, Barriers,…‘” by Johannes Unterguggenberger, availability means that value is loaded into the L2 cache (shared between multiprocessors). Visibility then refers to the L1 cache (separate for each multiprocessor). After the GPU’s processing unit writes a value, only its respective L1 cache is updated. So, we lose availability and have to go through the “make it available and then make it visible” process again. Chapter 7 of Vulkan specification:
“Availability operations cause the values generated by specified memory write accesses to become available to a memory domain for future access. Any available value remains available until a subsequent write to the same memory location occurs (whether it is made available or not) or the memory is freed. […] Visibility operations cause values available to a memory domain to become visible to specified memory accesses.”
More details are in the specification’s Appendix B - which describes the Vulkan memory model. The whole thing is above my pay grade.
To not dwell more on the intricacies of the system, VkAccessFlagBits2 are a part of every memory dependency barrier. After the write, to make its result available and visible, we need to provide access scope. This is defined as a tuple of VkPipelineStageFlagBits2 and VkAccessFlagBits2. It is specified for both 1) an operation that does the write and 2) a subsequent operation. In VkMemoryBarrier2:
srcStageMask,srcAccessMask. Define access scope for an operation that does the write. OnlyVkAccessFlagBits2that end with*_WRITE_BITmake sense here. If this operation is a read, you do not needmemory dependencyin the first place. OnlysrcStageMaskforexecution dependencywould have sufficed.dstStageMask,dstAccessMask. Define access scope for a subsequent operation, either read (read-after-write) or write (write-after-write).
Not all pairs of VkPipelineStageFlagBits2 and VkAccessFlagBits2 are valid. Please refer to VkAccessFlagBits2 docs for more details. It’s tedious to use, but at least gives some guidance and intuition on how to write synchronization code. E.g. for VK_ACCESS_2_DEPTH_STENCIL_ATTACHMENT_WRITE_BIT, the docs will hint that stages you look for are VK_PIPELINE_STAGE_2_EARLY_FRAGMENT_TESTS_BIT or VK_PIPELINE_STAGE_2_LATE_FRAGMENT_TESTS_BIT (for this particular case I would include both). All 4 fields are masks - you can combine several VkAccessFlagBits2 or VkPipelineStageFlagBits2. Vulkan validation layers will scream at you if you use an invalid combination.
Barrier types wrt. resource type
vkCmdPipelineBarrier2() places distinction on different types of resources that the barrier affects. This allows for optimizations e.g. stall reads from only part of the buffer instead of the whole. We have:
- Global memory barriers (VkMemoryBarrier2). Refers to all images and buffers used in the queue. The only parameters are
srcStageMask,srcAccessMask,dstStageMask,dstAccessMask. - VkBufferMemoryBarrier2. Extends
VkMemoryBarrier2with the following fields:buffer. Buffer affected by the memory dependency.offset,size. Affected subregion of the buffer.VK_WHOLE_SIZEis a special constant that denotes the subregion fromoffsetto buffer end.srcQueueFamilyIndex,dstQueueFamilyIndex. Used if we want to transfer buffer’s queue family ownership. Can be ignored withVK_QUEUE_FAMILY_IGNORED.
- VkImageMemoryBarrier2. Extends
VkMemoryBarrier2with the following fields:image. Image affected by memory dependency.subresourceRange. A VkImageSubresourceRange structure describing the affected mipmap level and array layer.oldLayout,newLayout. Used for image layout transitions. Like it or not, you will have to become intimately familiar with image layouts sooner or later. It’s a complicated topic that we will discuss in “Vulkan resources”.srcQueueFamilyIndex,dstQueueFamilyIndex. Used if we want to transfer buffer’s queue family ownership. Can be ignored withVK_QUEUE_FAMILY_IGNORED.
Synchronizing frames in flight and swapchain images
When creating the swapchain, we have also specified uint32_t minImageCount. This parameter is used to hint how many swapchain images we would like to create. Usually, you will have 2 (double buffering) or 3 images (triple buffering).
A similar, but unrelated term is frames in flight. The main idea is that when the GPU is processing commands for frame N, the CPU constructs a list of commands for frame N+1. While this sounds simple, there are some less obvious implications. If the GPU uses a buffer to render a frame, you should not override its content from the CPU at the same time. The easiest solution is to have separate copies per each possible frame in flight. This only applies to resources that are accessed both from the CPU and GPU, like uniform buffers (e.g. CPU updates view matrices). Each frame in flight has its own command buffers and synchronization objects (which we will see shortly). While you can choose as many frames in flight as you want, it’s almost always going to be either 1 (stall CPU after each frame to not override current values) or 2 (ping-pongs between 2 sets of objects).
Finding all resources written to from CPU might seem daunting. Until you realize that most CPU writes are done to mapped resources. Treat it as a hint that such resources might have to be duplicated for each
frame in flight. As we will see in “Vulkan resources”, using mapped memory that is never changed is suboptimal.
The terminology here can get a bit loose, especially on forums. A
frame in flightoften refers to the single frame that the GPU is working on right now. A CPU might be working on the next frame, but since it’s not the frame that the GPU is working on, it’s not called in-flight. When researching this topic, a lot of times you will have to read between the lines to guess the author’s intent. Both this article and the Vulkan tutorial defineframes in flightas how many frames are being worked on concurrently (either by GPU or CPU). It’s even more confusing when people equateframes in flightwithswapchain imagescount.
The concepts for swapchain image count and frames in flight met when the rendering output is written to the swapchain image. In most apps, there are 2 frames in flight and 3 swapchain images. Let’s see how it can look in such a case:
| Frame idx | Frame in flight idx | Swapchain image idx |
|---|---|---|
| N | 1 | 2 |
| N+1 | 0 | 0 |
| N+2 | 1 | 1 |
| N+3 | 0 | 2 |
| N+4 | 1 | 0 |
| N+5 | 0 | 1 |
Comparison between the frame in flight and swapchain image indices.
As you can see, there is no dependency between the used swapchain image and the current frame in flight. From the frame in flight's point of view:
- it acquires an image to draw to,
- it may depend on memory resources used by other
frames in flight. If you have 2frames in flight, each odd (e.g. N, N+2, N+4) frame will share uniform buffer memory.
There will be certain objects created for each frame in flight (command and uniform buffers, fences, image acquire and render complete semaphores, etc.) and some for each swapchain image (e.g. image views).
If you are using VSync, you want to 1) deliver a new frame for each VSync event, and 2) start the frame as late as possible. Starting the frame as late as possible guarantees that we will show the latest state. If you have some game logic or CPU-side simulations or even input handling, you do not want to present to the user a state that is ~16ms old (assuming a 60Hz monitor). Instead, you can calculate that it takes e.g. 4ms to produce a frame. In that case, you wait on the CPU for 12ms and then render a frame in 4ms. That frame is then presented to the user reflecting the latest possible state. Keep in mind that a delay between user input and reaction can make people dizzy (especially in VR). While simplified, this description should give you a better understanding of some of the challenges.
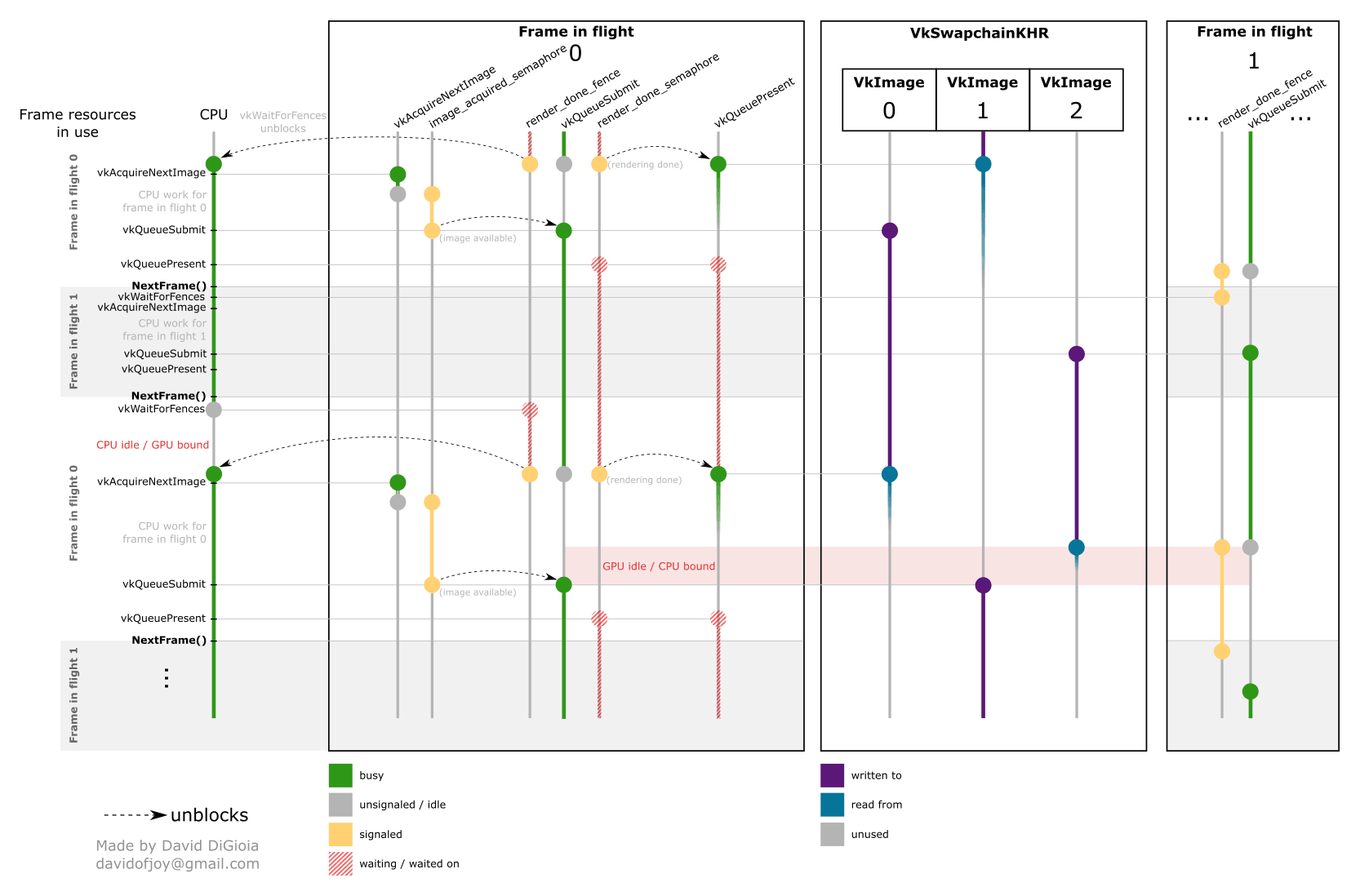
Example render loop sequence. Image by David DiGioia’s vulkan-diagrams. Available under MIT License.
Offscreen framebuffers
Offscreen framebuffer is a framebuffer whose attachments are only
VkImagesthat we have allocated. I.e. they are framebuffers that do not containswapchain images.
Offscreen framebuffers are a bit of a special case. It would be bad if both frame N and frame N+1 started writing to the same image. Turns out, this will never happen. You have to consider this from the perspective of VkQueue. First, frame N submits its commands. It uses certain images as attachments. Then, frame N+1 takes the same images and also tries to use them as render targets. But before that, it inserts the pipeline barriers. This would be either write-after-write or write-after-read barrier (depending on the last operation from the previous frame). Never duplicate framebuffers and their attachments. Neither frames in flight nor swapchain images matter here.
As both frame N and N+1 do vkQueueSubmit(), you might consider adding a semaphore to prevent commands from both submits running at once. In practice, I was not able to find any codebase that does this.
Swapchain image (as the name suggests), cannot be a part of an off-screen framebuffer. You have to create 1 framebuffer per each swapchain image.
Synchronization between frames in Vulkan
To draw a single frame, the following operations must be completed, usually in the following order:
- Wait (on CPU -
vkWaitForFences()) for the previousframe in flightthat used the same resources as the current frame. It’s a previous frame if there is 1frame in flight, and it’s previous-previous frame if there are 2. - Update resources like uniform buffers, etc.
- Record commands in the
command buffer(draws, compute dispatches, etc.). - Acquire from swapchain the image we will draw to (
vkAcquireNextImageKHR()). - Submit
command buffersto thequeueto execute (vkQueueSubmit()). - Present the finished image to the user (
vkQueuePresentKHR()).
This corresponds to the following code in Rust (using Ash):
/// Increasing index of the frame (just add +1 at the end of the frame to it)let frame_id = self.total_frame_id;/// Contains objects needed for each frame in flightlet frame_data = self.frame_datas[frame_id % frames_in_flight];// CPU waits for previous framedevice.wait_for_fences(&[frame_data.queue_submit_finished_fence],true,u64::MAX,).expect("vkWaitForFences()");// Reset fence so that it can be reuseddevice.reset_fences(&[frame_data.queue_submit_finished_fence]).expect("vkResetFences()");// Update uniform buffers for this frame in flight e.g. view matrices.// Record commands to frame_data.command_buffer// ...// Acquire an image. Pass in a semaphore to be signaled.// Potentially blocking if no image is availablelet swapchain_image_index: usize = swapchain_loader.acquire_next_image(swapchain,u64::MAX,frame_data.acquire_semaphore,vk::Fence::null(),).expect("Failed to acquire next swapchain image").0 as _;// Submit command buffers (non blocking)let submit_info = vk::SubmitInfo::builder().command_buffers(&[frame_data.command_buffer]).wait_dst_stage_mask(&[vk::PipelineStageFlags::COLOR_ATTACHMENT_OUTPUT]).wait_semaphores(&[frame_data.acquire_semaphore]).signal_semaphores(&[frame_data.rendering_complete_semaphore]).build();device.queue_submit(queue, &[submit_info], frame_data.queue_submit_finished_fence).expect("vkQueueSubmit()");// Present images for display (non blocking unless sometimes on Android)let present_info = vk::PresentInfoKHR::builder().image_indices(&[swapchain_image_index]).swapchains(&[swapchain]).wait_semaphores(&[frame_data.rendering_complete_semaphore]).build();swapchain_loader.queue_present(queue, &present_info).expect("vkQueuePresent()");self.total_frame_id = self.total_frame_id + 1;
The first step is to wait, as we should not update GPU memory while it’s still in use. For a single frame in flight, we essentially wait for the previous frame to finish. For 2 frames in flight, we wait for a fence from 2 frames ago. We can then record the commands (using multithreading if needed) and update uniform buffers. Since the commands will draw to the swapchain image, we have to acquire it first. Call vkAcquireNextImageKHR() (potentially blocking if no image available) and tell it to signal acquire_semaphore. Submit the commands for execution. In the vkQueueSubmit() function specify wait_semaphores(&[acquire_semaphore]) and signal_semaphores(&[rendering_complete_semaphore]). After the rendering is done (rendering_complete_semaphore), the finished frame is presented to the user (the exact present behavior depends on VkPresentModeKHR).
There are the following synchronization objects:
acquire_semaphore- signaled when: we have acquired the
swapchain imageto which we will draw in this frame, - waited on: before we will render to the
swapchain image,
- signaled when: we have acquired the
rendering_complete_semaphore- signaled when:
vkQueueSubmit()ends, which means that theswapchain imagecontains the rendering result, - waited on: before we will
vkQueuePresentKHR()the finished frame to the user,
- signaled when:
queue_submit_finished_fence- signaled when:
vkQueueSubmit()ends, which means that all commands have been finished and we will no longer use per-frame in flightresources, - waited on: before we use any per-
frame in flightresources (uniform/command buffers etc.).
- signaled when:
The exact ordering of the first few steps might be different depending on the application. Both vkAcquireNextImageKHR() and vkWaitForFences() can block CPU thread. Usually, vkAcquireNextImageKHR() is called as late as possible (just before we render to the swapchain image). On some OSes vkQueuePresentKHR() may also block.
According to Tobias Hector’s “Keeping your GPU fed without getting bitten”, if
vkQueueSubmit()andvkQueuePresent()operate on the same queue, there is no need forrendering_complete_semaphore.
Frames in flight and swapchain images in kajiya
Let’s dissect EmbarkStudios’ kajiya (written mostly by Tomasz Stachowiak):
Setup
- Triple buffering swapchain images
- Swapchain.acquire_semaphore, Swapchain.rendering_finished_semaphore
- DeviceFrame - per frame in flight resources. Stored as Device.frames
: [Mutex<Arc<DeviceFrame>>; 2]
Render loop
The following operations are executed inside renderer.draw_frame() (frame0 refers to current DeviceFrame):
- device.begin_frame()
- Recording and submitting command buffers - this is done before
acquire_next_image()! - swapchain.acquire_next_image()
- Recording and submitting command buffers - presentation commands only
- swapchain.present_image()
- device.finish_frame()
You can notice that kajiya has 2 command buffers. The first (main_cb), contains most of the rendering commands. After it is submitted, vkAcquireNextImageKHR() is called. The second command buffer (named in code as a “presentation command buffer” - presentation_cb) contains passes writing to the swapchain image.
The render graph implementation is quite interesting too. Initially, all passes are stored in a flat array. During RenderGraph.record_main_cb(), the index of the first pass writing to the swapchain image is calculated. All passes before that index record their commands into main_cb. RenderGraph.record_main_cb() then returns, submits the commands, swapchain image is acquired, and RenderGraph.record_presentation_cb() starts recording presentation_cb.
If you want to see all operations from the start: main loop while running {...}.
Khronos Group also has synchronization examples for swapchain image acquire and present. It features e.g. VK_PIPELINE_STAGE_COLOR_ATTACHMENT_OUTPUT_BIT execution dependency inside VkSubmitInfo. It functions as an additional check next to acquire_semaphore. Turns out, vkAcquireNextImageKHR() is allowed to return an image for which commands have been submitted but not finished executing. The vkAcquireNextImageKHR() is also allowed to return images out of order (pImageIndex has a value that is not a simple pImageIndex = (pImageIndex + 1) % swapchainImageCount).
Synchronization in practice
Q: How to choose the right synchronization method?
To synchronize between commands inside a single queue choose between a pipeline barrier or VkEvent. Use VkSemaphore for synchronization between queues. VkFence stalls the CPU thread till some particular event passes. Finally, vkDeviceWaitIdle() and vkQueueWaitIdle() wait on the CPU thread to completely drain the device/queue commands.
Q: I am confused by the access scope. Where can I find examples of Vulkan barriers?
Khronos Group has a list of the most common use cases in its GitHub “Synchronization Examples” post. It has subsections for all combinations of compute/graphic cases. It’s really good.
Examples from Rust-Vulkan-TressFX:
- wait_for_previous_frame_in_flight(),
- acquire_next_swapchain_image(),
- queue submit,
- queue present,
- Images
- the barrier between a render pass and compute shader that will modify the storage buffer,
- the barrier between 2 compute shaders,
- the barrier between compute shader and vertex shader,
- wait at the end of the setup command buffer,
- stalling CPU to get query results for the GPU profiler,
- drain work before exiting the app.
Q: How do I choose access scope after a command?
There are many commands other than vkCmdDraw() and vkCmdDispatch() that affect GPU memory. They need a barrier too. Sometimes it’s listed in the command’s docs e.g. vkCmdFillBuffer() says:
“vkCmdFillBuffer is treated as a “transfer” operation for the purposes of synchronization barriers.”
Sometimes you can find it in docs for VkAccessFlagBits e.g.
“VK_ACCESS_TRANSFER_WRITE_BIT specifies write access to an image or buffer in a clear or copy operation. Such access occurs in the VK_PIPELINE_STAGE_2_ALL_TRANSFER_BIT pipeline stage.”
If that fails, search for this command in Sascha Willems’ Vulkan examples repo.
Q: How to debug pipeline barriers?
Here are a few things you can try:
- Use a global barrier that has
VK_PIPELINE_STAGE_ALL_COMMANDS_BIT. - Check Vulkan validation layers. Overview by Jeremy Gebben and John Zulauf: “Ensure Correct Vulkan Synchronization by Using Synchronization Validation”.
- Create an option that will render only the first frame and exit the app. Add debug logs to everything e.g. image layout transitions, buffer barrier ranges, etc.
- Use tools offered by IHV e.g. AMD’s Radeon Graphics Profiler and NVIDIA Nsight Graphics for NVIDIA.

Vulkan validation layer detects “Hazard READ_AFTER_WRITE”.
Q: Can you write a pipeline barrier for me?
The combination of VK_IMAGE_LAYOUT_*, VK_PIPELINE_STAGE_*, VK_ACCESS_* is tricky. Fortunately, there are libraries that combine them into a single value. Tobias Hector’s “simple_vulkan_synchronization” fits in a single C header file. By using THSVS_ACCESS_FRAGMENT_SHADER_READ_SAMPLED_IMAGE_OR_UNIFORM_TEXEL_BUFFER we describe a sampling image in a fragment shader. THSVS_ACCESS_COLOR_ATTACHMENT_WRITE expresses color attachment write. Based on the previous and next THSVS_ACCESS_* values the library can:
Tomasz Stachowiak wrote a pure Rust alternative in vk-sync-rs.
Q: What’s the runtime cost of barriers?
You may stall GPU execution while waiting for previous work to finish. Our goal is to saturate the GPU with work. Few tips:
- Batch many barriers at once. With vkCmdPipelineBarrier2() each of
VkDependencyInfoobjects can contain many differentsrcStageMask/dstStageMask. In the previous version’s vkCmdPipelineBarrier() you only had onesrcStageMaskand onedstStageMask. If a graphic pass needs to do different layout transitions for different images it’s 2 differentvkCmdPipelineBarrier()calls. Of course, both calls would be one right after another, so it’s not a problem. But sometimes you also have to add a barrier for other resources e.g. after the buffer/storage image clears. This gets messy quickly. - Batching barriers could also minimize L2 texture cache flushes.
- Avoid over-synchronization. Detect if e.g. the image is already in the correct layout and skip the barrier.
- Be granular with
VkPipelineStageFlagBits. Suppose the first pass writes to an image and the second samples it in a fragment shader. We can run the 2nd pass’ vertex shader in parallel with the first pass. The barrier would havesrcStageMask=VK_PIPELINE_STAGE_COLOR_ATTACHMENT_OUTPUT_BITanddstStageMask=VK_PIPELINE_STAGE_FRAGMENT_SHADER_BIT. - Use
VkEvents and add more work between the points where memory dependency exists. This requires global frame knowledge. Either manually rearrange the pass order or write an algorithm that will do it for you. That’s exactly what render graphs were designed for. - Use a profiler to check at which points in the frame the GPU workload stalls. For AMD it’s Radeon Graphics Profiler and Nsight Systems for NVIDIA. There are also other 3rd party profilers available on the market.
Q: Do I have to add a barrier after writing to a mapped buffer?
After writing to the mapped buffer you first have to make the change available. This means that you either:
- call
vkFlushMappedMemoryRanges(), or - have created the allocation with
VK_MEMORY_PROPERTY_HOST_COHERENT_BIT(which automatically flushes).
Then you record the commands and call vkQueueSubmit(). According to Vulkan 1.3 specification, chapter 7.9. “Host Write Ordering Guarantees”:
“When batches of command buffers are submitted to a queue via a queue submission command, it defines a memory dependency with prior host operations, and execution of command buffers submitted to the queue.
The first synchronization scope includes execution of vkQueueSubmit on the host and anything that happened-before it, as defined by the host memory model.
The second synchronization scope includes all commands submitted in the same queue submission, and all commands that occur later in submission order.
The first access scope includes all host writes to mappable device memory that are available to the host memory domain.
The second access scope includes all memory access performed by the device.”
So, the answer is no, you do not need a barrier between writing to a mapped memory and calling vkQueueSubmit(). If this does not fit your scenario (e.g. vkQueueSubmit() before a write) then yes, the data may not seem up to date when read on the GPU. In that case, you can:
- Insert vkCmdWaitEvents2() (with
srcAccessMask=VK_ACCESS_2_HOST_WRITE_BIT) into a command buffer. - Call
vkQueueSubmit(). - Write to the mapped memory and flush it.
- Signal the event from the CPU with vkSetEvent().
It would be slow (you are waiting for the CPU) but should work OK. Sources:
- https://community.khronos.org/t/updating-uniforms-via-staging/7048/8
- https://stackoverflow.com/questions/48667439/should-i-syncronize-an-access-to-a-memory-with-host-visible-bit-host-coherent
- https://stackoverflow.com/questions/54653824/synchronizing-vertex-buffer-in-vulkan
Q: Any last tips?
- Bookmark in your browser Khronos Group’s samples. It lists tons of examples for different synchronization scenarios. You will reference it often.
- Scroll through Vulkan 1.3, chapter 7. It’s far from perfect, but it’s somewhat readable. Amusingly the chapter is titled “Synchronization and Cache Control”, but the word ‘cache’ appears only 3 times. There is also Appendix B: Memory Model that tries to lure you into more details.
- VK_KHR_synchronization2 has an easier API than the original synchronization. It allows to specify
srcStageMask,srcAccessMask,dstStageMask, anddstAccessMaskinside a single VkMemoryBarrier2 object.
Summary
In this article, we have discussed different synchronization methods in Vulkan. The most common are pipeline barriers, VkEvents, VkSemaphore, and VkFence. There are also vkDeviceWaitIdle(), vkQueueWaitIdle(), and the VK_KHR_timeline_semaphore. We went over execution and memory dependencies with the initially confusing pipeline stages and access flags. We now also know what frames in flight are and how to synchronize them with the swapchain mechanism.
Time to put this knowledge into practical use. In “Vulkan resources” we will discuss VkBuffers and VkImages.
References
- Khronos Group’s samples
- VK_KHR_synchronization2
- Hans-Kristian Arntzen’s “Yet another blog explaining Vulkan synchronization”
- Johannes Unterguggenberger’s “Understand Fences, Semaphores, Barriers,…”
- Khronos Group’s “Understanding Vulkan Synchronization”
- Arseny Kapoulkine’s “Writing an efficient Vulkan renderer”
- Yuriy O’Donnell’s “FrameGraph: Extensible Rendering Architecture in Frostbite”
- John Zulauf’s “How to Use Synchronization Validation Across Multiple Queues and Command Buffers”
- Tobias Hector’s “simple_vulkan_synchronization”
- Embark Studios’s kajiya
- Jeremy Gebben’s and John Zulauf’s “Ensure Correct Vulkan Synchronization by Using Synchronization Validation”
- Access scope:
- Frames in flight and swapchain synchronization
- “Synchronizing Frames in Flight”
- Michael Parkin-White, Calum Shield’s “Samsung - Live Long and Optimise”